Результаты тестирования Liteset
Параллельное сравнение Liteset (Litestar + Uvicorn, async) и Apache Superset 6.0.0 (Flask + Gunicorn, sync) на идентичном железе, данных и профиле нагрузки. Единственная переменная между прогонами — модель конкурентности бэкенда: оба стека работают на 4 воркерах против одного и того же ограниченного PostgreSQL 16 и набора данных SSB Scale Factor 10 (~60 млн строк). Полное описание стенда — на странице Методика.
Headline-метрики
Throughput (RPS)
↑ betterDashboard Fan-Out, 200 concurrent users
Median response time
↓ betterDashboard Fan-Out, 200 concurrent users
Error rate
↓ betterDashboard Fan-Out, 200 concurrent users
Throughput at 1 s I/O latency
↑ betterControlled IO Latency Sweep, 50 users
Четыре метрики вместе рассказывают одну историю: перенос веб-слоя с блокирующихся Gunicorn-воркеров на единый ASGI event loop меняет cost model IO-bound деплоя Superset. Пока один запрос ждёт 10–50-секундный аналитический запрос, async-воркер продолжает обслуживать другие; sync-воркер просто заблокирован на socket.recv() и не может принять новую работу.
Сценарий 1 — Dashboard Fan-Out
Моделирует типичную работу аналитика: загрузку дашборда с 3–13 чартами, каждый из которых порождает свой SQL-запрос к аналитической СУБД. Прогон при 200 одновременных пользователях, 15 минут.
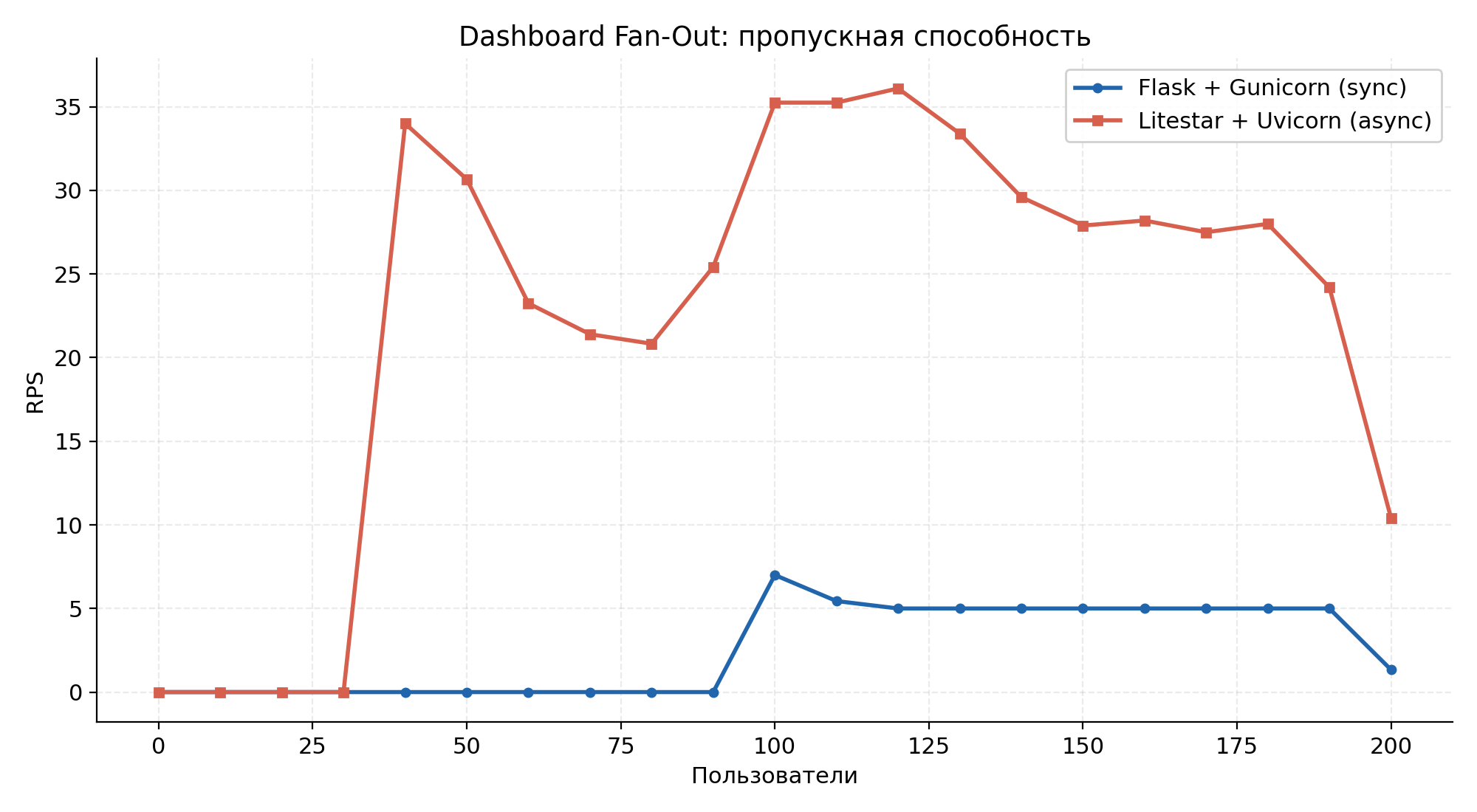
Рисунок 4.1 — Пропускная способность (RPS) на протяжении прогона.
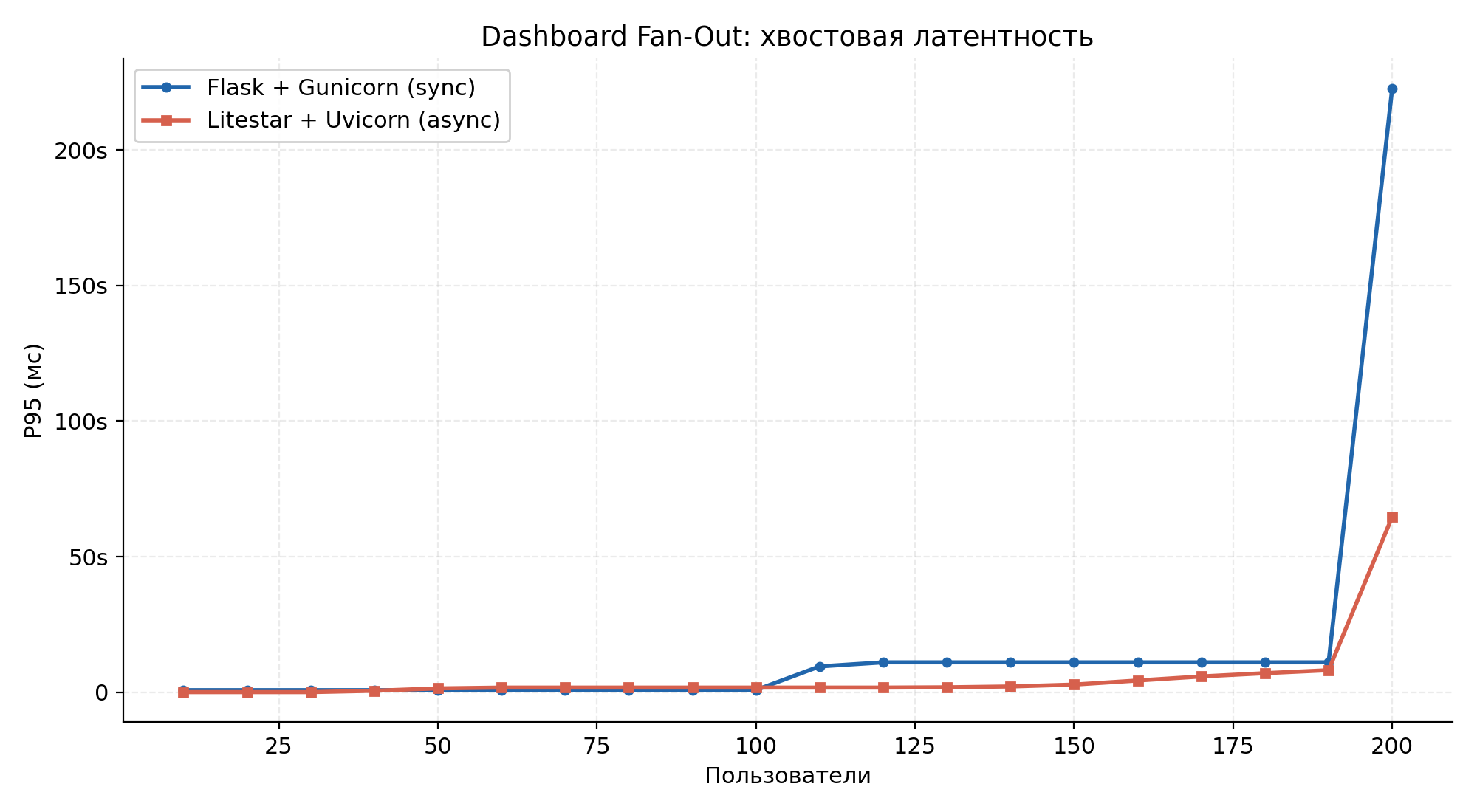
Рисунок 4.2 — Хвостовая латентность p95 на протяжении прогона.
| Метрика | Apache Superset (sync) | Liteset (async) | Δ |
|---|---|---|---|
| Запросов обработано | 1 129 | 9 510 | 8,4× |
| RPS (агрегат) | 1,27 | 10,57 | 8,3× |
| Медиана отклика (мс) | 134 000 | 4 500 | 29,8× |
| P95 (мс) | 300 000 (timeout) | 133 000 | 2,3× |
| Доля ошибок | 32,8 % | 7,4 % | −25,4 п.п. |
| CPU avg / max (%) | 12 / 169 | 121 / 386 | — |
| RAM max (МБ) | 856 | 900 | +5 % |
Пропускная способность выросла в 8,3 раза, медианная задержка упала со 134 с до 4,5 с (29,8×). В синхронной системе 132 из 200 запросов csrf_token — тривиальный вызов, не обращающийся к аналитической СУБД — завершились таймаутом, потому что все воркеры были заняты тяжёлыми запросами. Более высокое CPU у async-бэкенда (121 % avg против 12 %) отражает то, что Uvicorn активно работает в event loop, тогда как Gunicorn большую часть времени заблокирован на системных вызовах.
Сценарий 2 — SQL Lab Interactive Session
Моделирует работу дата-инженера, последовательно выполняющего SSB-запросы через API SQL Lab. Прогон при 50 одновременных пользователях, 10 минут.
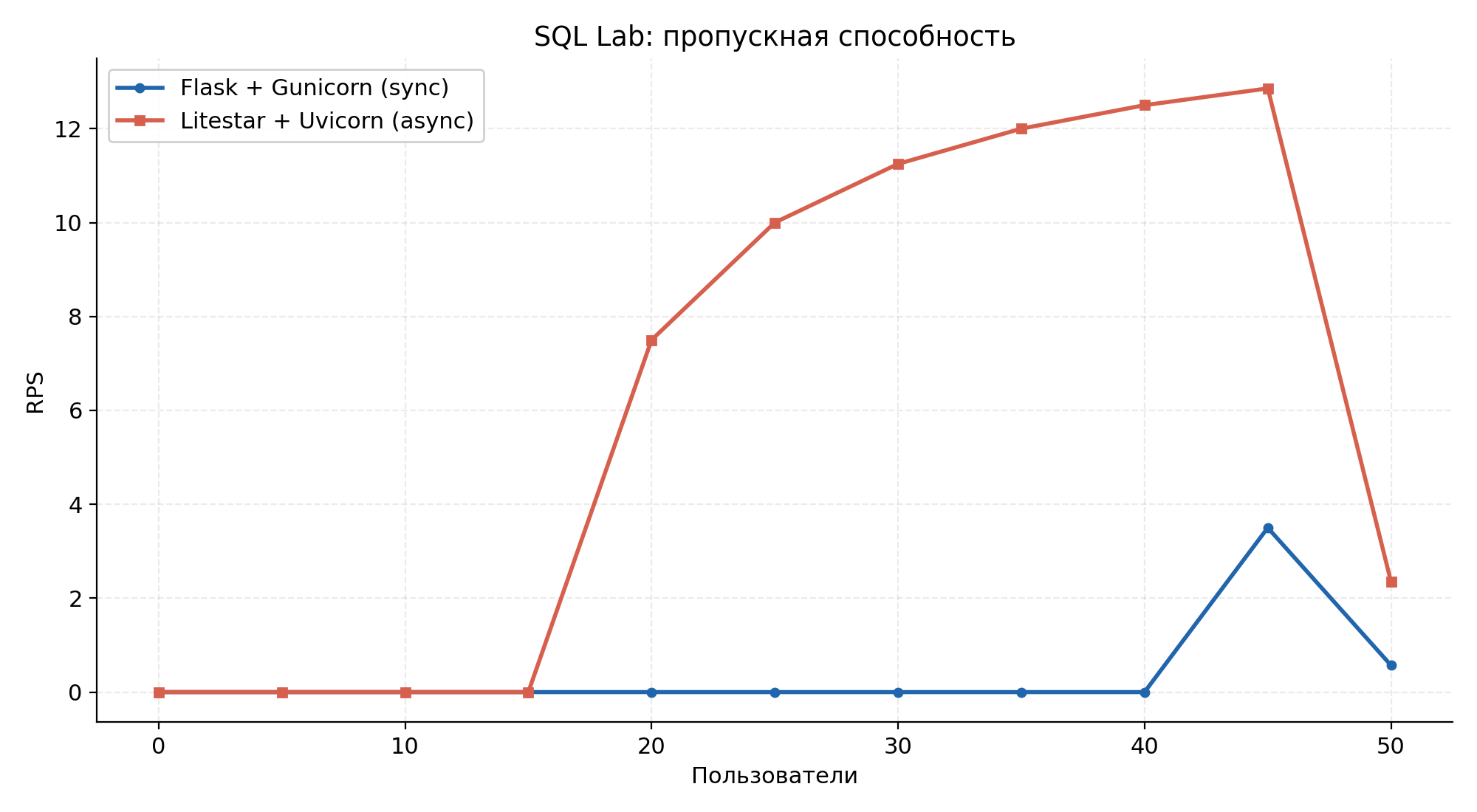
Рисунок 4.3 — Пропускная способность (RPS) на протяжении прогона.
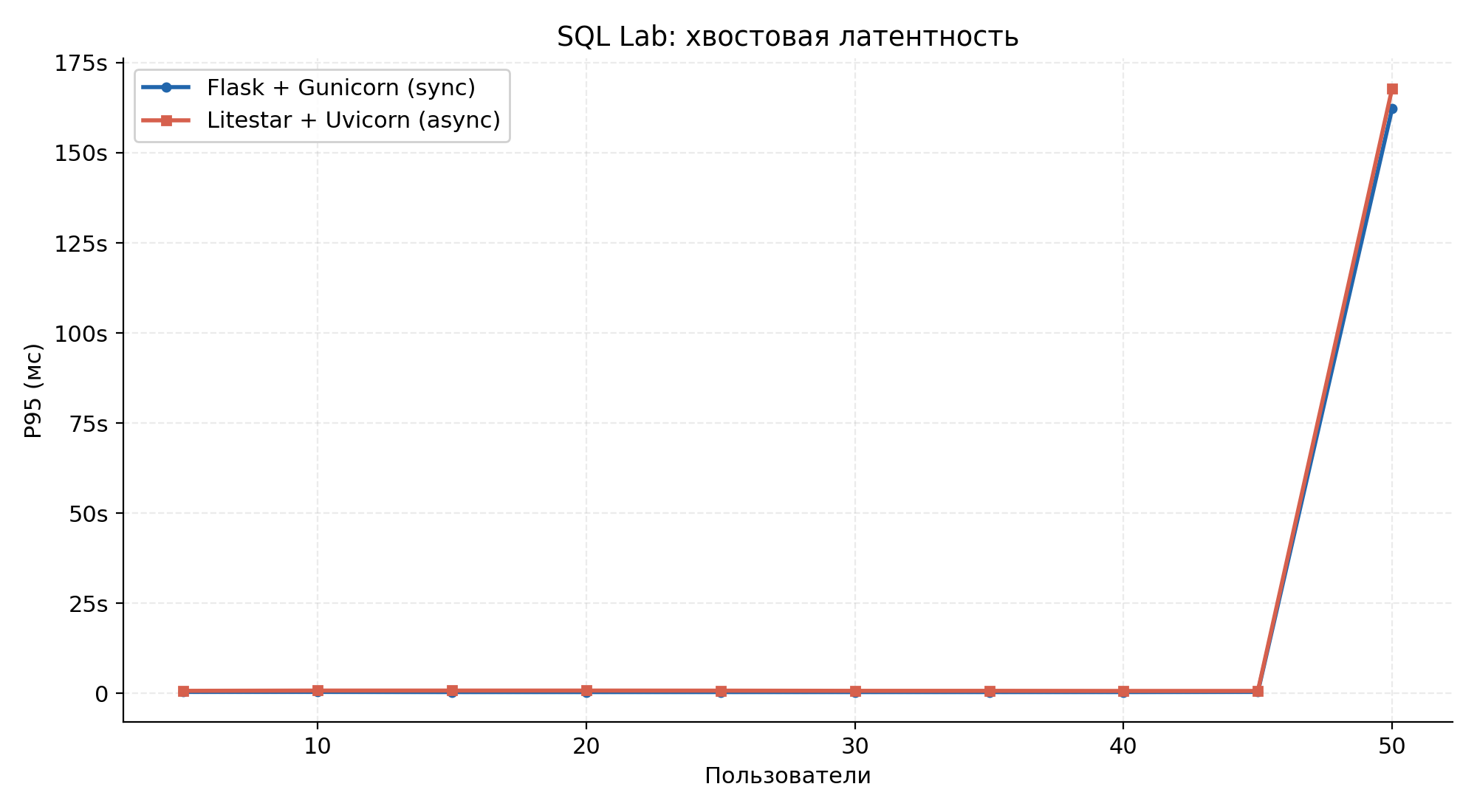
Рисунок 4.4 — Хвостовая латентность p95 на протяжении прогона.
Поскольку каждый пользователь выполняет запросы последовательно, а узкое место — PostgreSQL на 4 vCPU, пропускная способность тяжёлых запросов находится в паритете — это ожидаемый результат. Различие проявляется в отзывчивости инфраструктурных эндпоинтов, не обращающихся к аналитической СУБД:
Время отклика инфраструктурных эндпоинтов (медиана, мс):
| Эндпоинт | Apache Superset (sync) | Liteset (async) | Δ |
|---|---|---|---|
/security/csrf_token | 810 | 13 | 62× |
/security/login | 26 000 | 380 | 68× |
/database/ | 1 800 | 190 | 9,5× |
Сводные результаты:
| Метрика | Apache Superset (sync) | Liteset (async) | Δ |
|---|---|---|---|
| Запросов обработано | 262 | 262 | — |
| Ошибки | 10 (3,8 %) | 9 (3,4 %) | −0,4 п.п. |
| P95 агрегат (мс) | 291 000 | 278 000 | −4,5 % |
| Медиана SSB-запросов (мс) | 135 000–184 000 | 101 000–233 000 | ≈ паритет |
| CPU avg / max (%) | 3,8 / 97 | 5,5 / 223 | — |
| RAM max (МБ) | 822 | 975 | +19 % |
В синхронном стеке лёгкие эндпоинты деградируют на два порядка под нагрузкой — медиана csrf_token выросла до 810 мс и достигла 103 с на P90, а login занял 26 с. Для пользователя это разница между интерфейсом, который «висит» при входе, и интерфейсом, мгновенно реагирующим на навигацию, пока аналитические запросы выполняются на фоне.
Сценарий 3 — Controlled IO Latency Sweep
Изолирует влияние IO-латентности на пропускную способность, заменяя реальный SQL на pg_sleep с фиксированными задержками (10 мс – 5 с). Прогон при 50 одновременных пользователях, по 2 минуты на каждое значение задержки. Это наиболее чистое сравнение архитектур, поскольку вариативность СУБД исключена полностью.
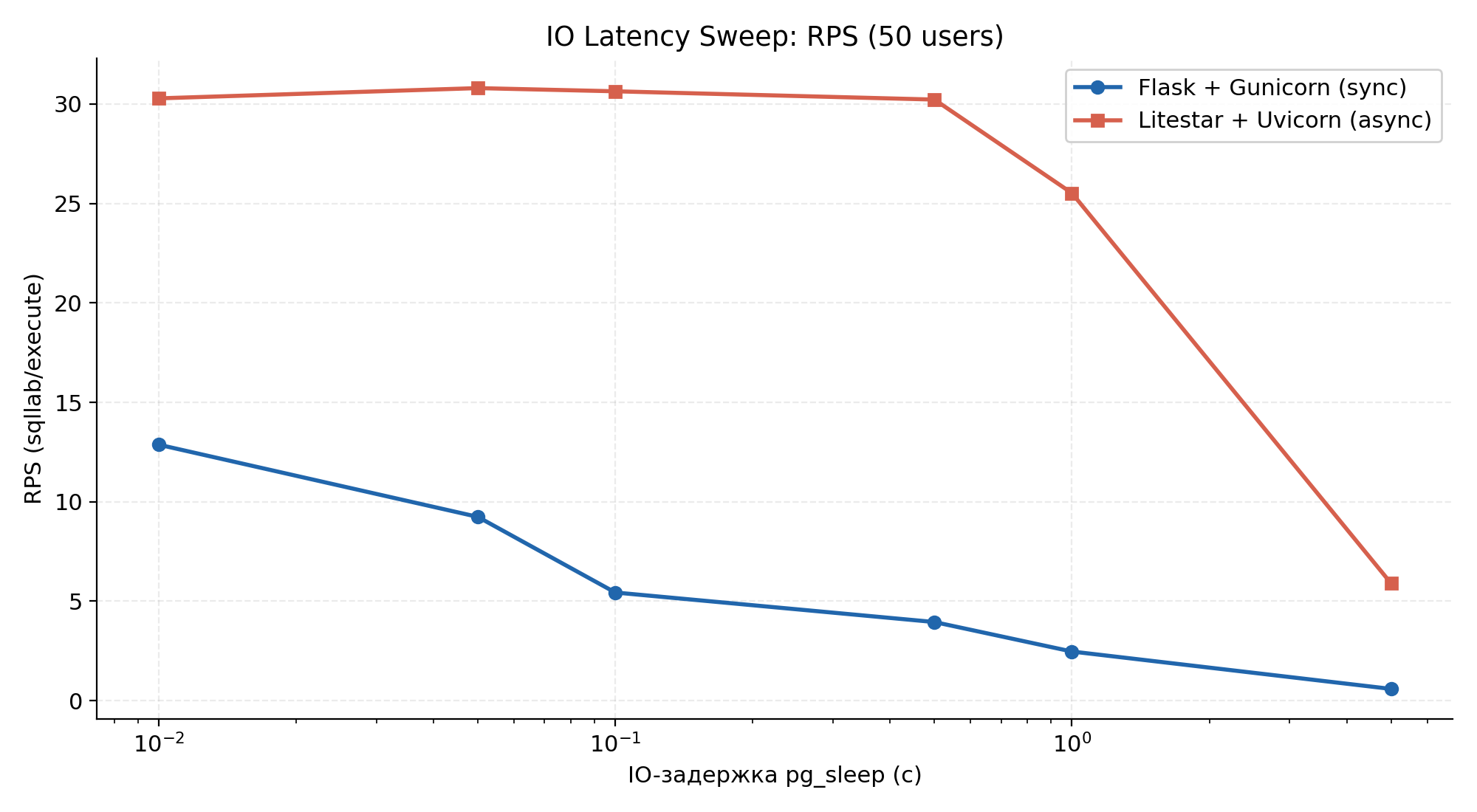
Рисунок 4.5 — Пропускная способность (RPS) от управляемой IO-задержки pg_sleep (логарифмическая ось X).
RPS при каждом значении IO-задержки (50 пользователей):
| IO-задержка | Apache Superset RPS | Liteset RPS | Кратность |
|---|---|---|---|
| 10 мс | 12,87 | 30,29 | 2,4× |
| 50 мс | 9,24 | 30,80 | 3,3× |
| 100 мс | 5,44 | 30,64 | 5,6× |
| 500 мс | 3,95 | 30,23 | 7,7× |
| 1 с | 2,47 | 25,52 | 10,3× |
| 5 с | 0,59 | 5,90 | 10,0× |
Async-пропускная способность остаётся практически постоянной (~30 RPS) от 10 мс до 500 мс — event loop просто переключается между корутинами в точках await. Sync-пропускная способность падает пропорционально задержке, отслеживая теоретический предел 4 воркера / задержка (например, ~4 RPS при 1 с). Преимущество растёт с IO-латентностью и достигает 10× при 1–5 с — именно в этом режиме работают BI-платформы. Снижение до 25,52 RPS при 1 с и 5,90 RPS при 5 с на Liteset — это насыщение пула соединений asyncpg, а не event loop.
Память
Согласно отчёту о тестировании, резидентная память в сценарии Dashboard Fan-Out составила 900 МБ у Liteset против 856 МБ у Apache Superset (+5 %), что объясняется хранением состояния корутин и пула соединений asyncpg. По критерию готовности НФТ-2 (RSS ≤ baseline × 1,15) это зафиксировано как выполненное.
Оговорки
- Это макро-бенчмарки end-to-end поведения бэкенда, а не скорости конкретного SQLAlchemy-запроса или роутины рендера графика.
- PostgreSQL намеренно ограничен по ресурсам (4 vCPU против ~60 млн строк), чтобы аналитические запросы занимали 5–50 с. Это делает нагрузку IO-bound — режим, в котором async-модель помогает больше всего и в котором живут реальные BI-деплои.
- Оба стека работают на 4 воркерах, чтобы изолировать модель конкурентности как единственную переменную между прогонами.
- Поведение фронтенда идентично by design; ничто здесь не измеряет время рендера.
Воспроизведение
Железо, тюнинг PostgreSQL, набор SSB SF=10 и Locust-скрипты описаны на странице Методика. Полные CSV-выгрузки Locust (stats, stats_history, failures) и снимки docker stats для каждого прогона приведены в дипломном отчёте о тестировании; каждый сценарий повторялся 3 раза для статистической устойчивости.